
 Tim Loveless | Principal Solutions Architect
Tim Loveless | Principal Solutions Architect
Adjusting System Functionality and Capabilities in LYNX MOSA.ic
I recently set up a demo to showcase how a customer can use subjects, also known as rooms, like containers. What I mean by that is that software...
Multicore safety research from Barcelona Supercomputer Centre (BSC) says that a robustly partitioned hardware and software platform is practically impossible. With today’s multicore processors (MCPs), current RTOS, and hypervisor technology Dr. Francisco Cazorla sees no path to robust partitioning. Lynx worked with Dr. Cazorla on the MASTECS MCP research project and agrees with that assessment.
Robust partitioning is defined by EASA, the European Union Aviation Safety Agency, in AMC 20-193 -Use of multi-core processors. This document describes an acceptable means of compliance to achieve safety certification of MCPs in airborne systems. The aviation industry has spent tremendous effort on the challenges building safe multicore systems. AMC 20-193 is EASA’s formal adoption of the preceding CAST-32A paper and is essentially identical with respect to MCP processor guidance. Robust partitioning is important because it allows composability of certified software partitions (SWPs). It allows one SWP to be safety certified independently of the others and combinations of SWPs to be composed into larger multi-partition systems without having to recertify every time. MCP certification is still possible without robust partitioning, but it costs more. SWP reuse without re-certification is a key goal of Integrated Modular Avionics (IMA) (described in DO-297) that is broken on MCPs by the loss of robust partitioning.
BSC – Barcelona Supercomputer Centre
HSR – Hardware shared resource
MCP – Multicore processor
MMU – Memory management unit
RRP – Robust resource partitioning
RTOS – Realtime operating system
RTP – Robust time partitioning
SCP – Single core processor
SLAT – Second level address translation
SWP – Software partition
WCET – Worst-case execution time
BSC carefully examined robust partitioning as defined by CAST-32A and dissected how it applies to MCPs. This article is a commentary and summary of their findings.
To understand the BSC work we need an extract from CAST-32A. CAST-32A defines that robust partitioning requires both robust resource partitioning (RRP) and robust time partitioning (RTP). It says that RRP is achieved when:
And goes on to say that RTP is achieved when:
as a result of mitigating the time interference between partitions hosted on different cores, no software partition consumes more than its allocation of execution time on the core(s) on which it executes, irrespective of whether partitions are executing on none of the other active cores or on all the other active cores.
The key insight of the BSC work is that for a MCP to be robustly partitioned, all its shared HW subsystems must also be robustly partitioned. This makes intuitive sense since it only takes one interference channel to break robust partitioning. Following the definition of robust partitioning, we see that b. must apply to all hardware shared resources (HSRs).
Any hardware structure inside a MCP that is shared by the CPU cores is an HSR. The more you look for shared hardware in MCPs the more you find it. For example, using the Xilinx Zynq UltraScale+ block diagram we can follow the connectivity of the Arm Cortex-A53 CPU cores to see that the snoop control unit, accelerator coherency port, L2 cache, cache coherent interconnect, central switch, direct memory access controller, and DDR RAM are all HSRs. Reading the Xilinx Zynq UltraScale+ Technical Reference Manual reveals more, such as the bus interface unit, on-chip interconnect and translation control unit, and others may exist known to technical experts employed by Xilinx.
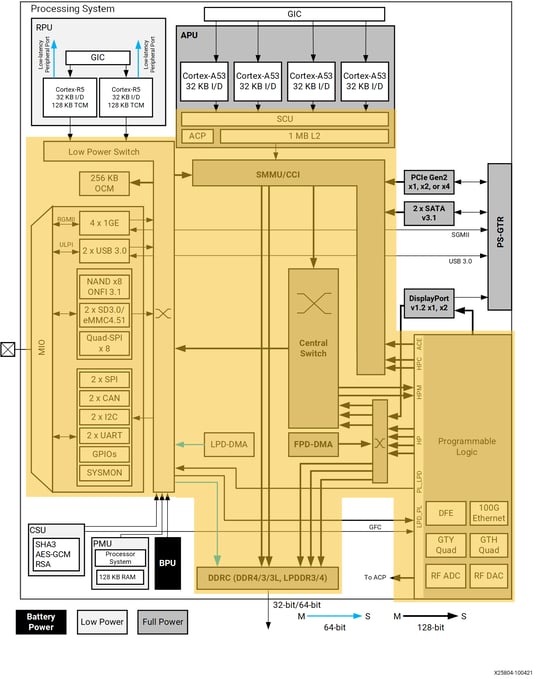
Figure 1 – Hardware Shared Resources (HSRs) highlighted on Xilinx ZYNQ UltraScale+ MPSoC block diagram
Restricting a SWP to its allocation of HSRs to achieve b. requires that a portion of each HSR can be allocated to each SWP. Whether and how this may be achieved is different for each HSR. For example, RAM can be cleanly allocated into disjoint regions, one per SWP. This is commonly done with a hypervisor using SLAT or an RTOS using the MMU. Cache can also be partitioned via either hardware support such as Intel’s CAT and ARM’s MPAM or with clever cache coloring software. Both RAM and cache are examples of explicit allocation. That is, the portion of the HSR the SWP is allowed to use is directly controlled. Note that we just mentioned four possible methods to partition RAM and cache and that they are completely different.
While in theory it is possible to build a MCP with explicit allocation for all HSRs, that conflicts with the design assumption of MCPs. They are built for the mainstream market where high performance on average is paramount. The cost of eliminating interference by replicating or explicitly partitioning all HSRs is high and offers no benefit to that market. So, HSRs are deliberately under-provisioned because average performance is better with more cores and tolerating some HSR contention. Unfortunately this creates a problem for safety-critical systems, since as defined by ARP4761, they must be built to the level of rigor such that the probability of failure is below 10−9 per flight hour; that is, 1 chance in 1,000,000,000 per hour (equivalent to 1 failure in 140,000 years). For this reason, even if it is rare, HSR contention must be quantified and mitigated if multi-core processors are to be used in safety-critical systems.
The majority of HSRs cannot be cleanly partitioned because they are implicitly allocated the instant a SWP accesses them. SWPs compete for this type of HSR typically on a first-come-first-served basis, and stall for numerous cycles if the HSR is busy. This makes restricting a SWP to its allocation of HSRs practically unachievable and is the root of our statement that robust partitioning is dead.
DRAM row buffers are an example of an implicitly allocated HSR. DRAM is typically divided into either 8 or 16 banks. Memory accesses can be made in parallel, but only if they are for different banks. Each bank is divided into many rows and has a dedicated row buffer. DRAM is structured as a matrix, every time a value is read the whole row is fetched. To do this, the row is opened and copied to the row buffer. At this point subsequent accesses within the same row can be served quickly, but if another row is accessed, the current row must first be closed before the new one can be opened. The Xilinx ZCU102 board has 4GB of DDR4 RAM operating at 333Mhz. Closing a row and opening another takes 112 clock cycles verses accessing an already open row which takes only 72, see UltraScale Architecture-Based FPGAs Memory IP Product Guide (PG150). Row buffers are allocated the instant they are needed to whichever CPU core makes the memory request. That CPU core will see a memory latency of either 72 of 112 memory clock cycles depending if the previous memory request used the same row or not.
With clever software it is possible to automatically discover the scheme used to map DRAM channel, rank, bank, row, and column to the address bus. The mapping used on modern CPUs is not simply one-to-one with the address bus lines. Instead, semiconductor manufacturers use XOR to combine various address bits so that common sequential accesses efficiently minimize row buffer conflicts. Michael Schwarz’s master’s thesis, DRAMA: Exploiting DRAM Buffers for Fun and Profit – August 2016, describes how to reverse engineer addressing schemes and how to use row buffer latency to build a covert communication channel between different CPU cores even if they share no memory range. Schwarz achieved a channel capacity of 2.3kbit/sec on an Intel Core i7 Ivy Bridge PC.
In theory it is possible to control implicitly allocated HSRs indirectly by restricting access to them, but there are many implicitly allocated HSRs, each needing different restrictions, that when combined with the inherent imprecision of indirect control, guaranteeing all are reliably allocated between SWPs is impractical.
The best we can do is to partially control an implicitly allocated HSR by indirectly restricting access to it by restricting how often or how long a SWP has HSR access. HSR temporal partitioning restricts how long a SWP can access HSR. HSR bandwidth partitioning restricts how often a SWP can access a HSR. The degree of success of these indirect techniques heavily depends on the HSR in question.
HSR temporal partitioning grants a SWP exclusive access to a HSR for a time period. HSR temporal partitioning can result in a high degree of isolation for HSR without memory and without eviction capabilities. This means temporal partitioning is insufficient for HSR such as cache since SWPs can evict each other’s cache content. If a cache is given to another SWP for a period of time, it will be returned with worse state than if it had not been shared. The effectiveness of HSR temporal partitioning can also be reduced by contention with latency, since HSR access late in the time window can result in contention bleeding across the boundary into the next time period.
HSR bandwidth partitioning limits the number of requests that can be performed during a period of time. An SWP can access the HSR as long as it has not consumed its budget. The caveats of HSR bandwidth partitioning relate to the granularity of the time windows. Coarse time windows allow more contention scenarios since requests have more freedom to spread or concentrate over time. Fine time windows share the HSR more fairly but result in underutilization.
Indirect approaches have been demonstrated. For example, using HW performance counters to monitor a SWP’s memory bandwidth usage, and throttling (descheduling) it should a threshold be exceeded. While this is achievable, it does not directly control the HSR so is somewhat fragile. Close care is required to tune the duration of bandwidth windows and quotas per SWP.
In some cases, partitioning implicitly allocated HSR can be avoided. If the HSR access time is small relative to its processing time, then worst-case assumptions can be made. For example, assume a HSR with a split data array but shared access port. If the access time is relatively short, e.g., 1 cycle and the processing time 10-20 cycles, then the worst-case impact due to contention is less than 10%. That is, the access time for this HSR can be assumed to be 10% higher than its access time in isolation.
Losing robust partitioning forces us to follow CAST-32A’s non-robustly partitioned platform objective:
All other MCP platforms:
Applicants may verify separately on the MCP any software component or set of requirements for which the interference identified in the interference analysis is mitigated or is precluded by design. Software components or sets of software requirements for which interference is not avoided or mitigated should be tested on the target MCP with all software components executing in the intended final configuration, including robustness testing of the interfaces of the MCP.
The WCET of a software component may be determined separately on the MCP if the applicant shows that time interference is mitigated for that software component; otherwise, the WCET should be determined by analysis and confirmed by test on the target MCP with all the software components executing in the intended final configuration.
This is a little longwinded but surprisingly it still permits separate verification (certification) of software components (SWPs) if interference is identified and mitigated. As expected, this verification must include WCET of software components. And as expected, if interference is not mitigated, then the entire system must be tested as a whole.
CAST-32A’s non-robustly partitioned platform objective is less prescriptive about how verification of interference mitigation is achieved, but the BSC researchers make the sensible assumption to follow as much of the robust partitioning guidance as they can anyway. If portions of the MCP can still be robustly partitioned that helps and examining the bits where robust partitioning is not possible assists with building mitigations for them. Also, while HSR temporal partitioning and HSR bandwidth partitioning techniques are insufficient to robustly partition an MCP, they are still useful. If you know the contention caused by a specific SWP, with tuning, those techniques can be targeted to mitigate it.
Lynx and BSC’s experience is that measuring contention and assessing the effectiveness of mitigations is best done using HW performance monitoring counters (PMCs). Such counters provide access to detailed internal MCP metrics intended for performance optimization and debugging. All MCPs Lynx is working with provide such counters. Typically, a handful of counters (6 on the PowerPC T2080) are provided, each of which can be configured to monitor one of several hundred metrics. Example metrics include processor cycles, instructions completed, L2 cache hits, interrupts taken, branches taken, branches mispredicted, data translation lookaside buffer miss cycles, FPU divide cycles, etc.
LESS CONTROL OF SOFTWARE PARTITION (SWP) BOUNDARIES
The difference with CAST-32A’s non-robustly partitioned platform objective is that we have less control over the boundaries of our SWPs. They must be set so that it is possible to mitigate or eliminate interference between them. The challenge is that the interference depends on the workload of each SWP. This creates a feedback loop. Moving SWP boundaries (shifting workloads) impacts the SWPs, which in turn changes interference. The same is true for mitigating interference. If it does not cleanly target one interference source, it changes the balance of the whole system.
Interference mitigation need not be only via intrusive HSR bandwidth partitioning. Careful analysis and scheduling of entire SWPs can achieve some HSR temporal partitioning at the macro level. Scheduling a memory-heavy SWP to co-run with an FPU-heavy SWP to reduce memory contention from two memory-heavy SWPs, for example. But macro-level SWP scheduling alone, as proposed by some RTOS vendors, is insufficient. Finding such a configuration requires deep timing analysis and experimentation over many iterations. The configuration will be specific to the number, mix, and execution profile of a specific project’s SWPs.
SWP boundaries and interference mitigations can easily be too conservative (too “safe”) so that the performance of an n-core MCP is below n SCPs, thus defeating the benefit of an MCP. The challenge of building a certifiable MCP system is one of design compromise. A configuration that combines conservative SWP placement with just enough interference mitigation so that collective SWP performance is maximized is needed. Overall, certifying a MCP system is like lassoing a herd of cattle and tightening the noose without hurting any of them.
There has been confusion around the term robust partitioning since 2005 when the first MCPs became available. This is understandable because RTOSes do already achieve robust partitioning on SCPs. On SCPs there is only one CPU core and so no hardware is shared (no HSRs). Context switching the CPU core between SWPs elegantly partitions the entire SoC. With RAM partitioned using the MMU, the only inter-SWP coupling is the residual state left in the hardware from the last SWP. In practice this residual is small and with rigid ARINC scheduling becomes predictable enough to be accounted for with a modest scheduling margin. In short, the caches and the branch predictor take time to warm up, but this is short and predictable, so can be accounted for.
Robust partitioning is an attractive marketing term that is commonly used in RTOS collateral, and that is completely accurate for SCPs. When MCPs started replacing SCPs in 2005 the robust partitioning claim gradually became inaccurate. As described here, the change is subtle and technical, so it is understandable that RTOS vendors were slow to realize their SCP robust partitioning implementations no longer applied, and they were even slower to remove the term from marketing material. MCP safety certification is very challenging, and since robust partitioning is the holy grail that makes it easy, there is strong naïve demand for a robustly partitioned RTOS or hypervisor. Lynx’s advice is to take any RTOS or hypervisor claim of multicore robust partitioning with a pinch of salt.
MCPs are built with HSRs that cause interference between simultaneously running SWPs. Most of these HSRs are implicitly allocated by the MCP the instant they are accessed and cannot be robustly partitioned between SWPs. This means that the MCP cannot support robust partitioning and that it cannot host an arbitrary mix of SWPs because the workload of one SWP can cause another to miss its deadline. However, it is still possible to build a safety certified MCP system, it just takes more work because the configuration, timing analysis, and contention mitigations are dependent on the SWPs running in the system. With detailed timing analysis using HW performance monitoring counters (PMCs) interference mitigation schemes can be built so that the MCP can safely host simultaneously running SWPs. The engineering challenge is to configure interference mitigation schemes with a sufficiently light touch to avoid defeating the MCP performance benefit.
To support designs following this advice Lynx encourages software partitioning using hypervisor virtual machines instead of RTOS partitions. Our hypervisor supports scheduling such virtual machines with an ARINC major-minor frame scheduler. Each application is hosted on a single-process unikernel in its own virtual machine. The unikernel provides the POSIX library, filesystem and network stack to service its application while avoiding the nested scheduler conflict a full RTOS would cause.
Multicore safety is an area of expertise and active innovation for Lynx Software Technologies. Multicore designs should be approached with caution and careful planning to understand the complexity and minimize risks. Our experience is that there are large pitfalls and no easy solutions. We are engaged in several multicore avionics design and research projects and would be delighted to discuss multicore safety and partitioning strategies for your next project.

I recently set up a demo to showcase how a customer can use subjects, also known as rooms, like containers. What I mean by that is that software...

Based on several customers inquiries the purpose of this blog is to outline how to Allocate memory to a RAM disk Mount and unmount a RAM disk ...

Not many companies have the expertise to build software to meet the DO-178C (Aviation), IEC61508 (Industrial), or ISO26262 (Automotive) safety...